Kafka Streams
Kafka Streams is a client library for building applications and microservices, where the input and output data are stored in an Apache Kafka cluster. It combines the simplicity of writing and deploying standard Java and Scala applications on the client side with the benefits of Kafka's server-side cluster technology.
Concepts
- KStream, KTable, GlobalKTable
- Log Compaction
- Stateful/Stateless Operations ( Windowing… )
- Re-partition
- Out-of-Order Handling/Out-of-Order Terminology
- Interactive Queries
- Time
Notes
- client.id parameter in regular kafka operations equals to application.id in kafka streams
- Don’t change application.id parameter
- You can scale stream application. But instance count must equal or lower than the partition count. Co-partitioned : the number of partition count must be equal on both side(KStream or KTable).
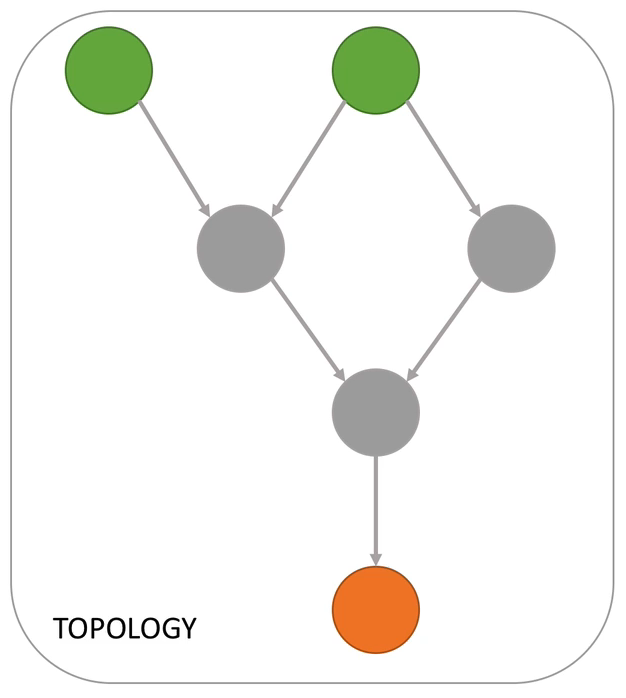
Processor Topology
A processor topology or simply topology defines the computational logic of the data processing that needs to be performed by a stream processing application.
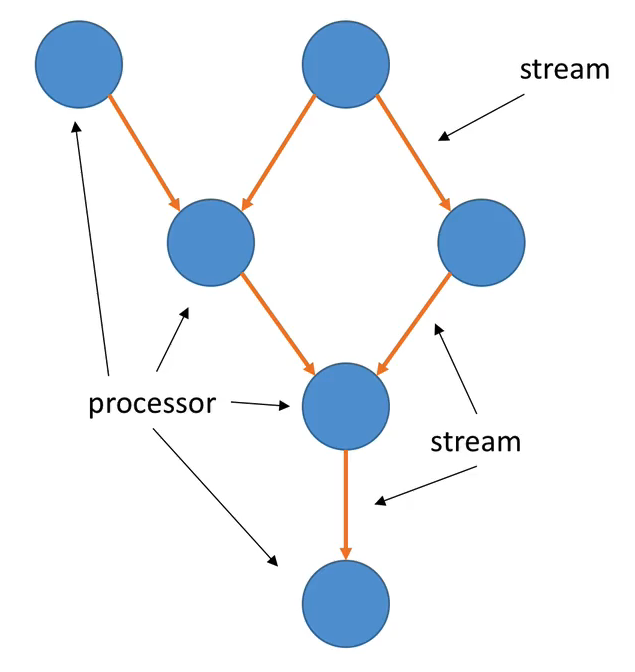
- A stream is a sequence of immutable data records, that fully ordered, can be replayed, and is fault tolerant (think of a Kafka Topic as a parallel)
- A stream processor is a node in the processor topology (graph). It transforms incoming streams, record by record, and may create a new stream from it.
- A topology is a graph of processors chained together by streams.
- A source processor is a special processor that takes its data directly from a Kafka topic. It has no predecessors in a topology and doesn’t transform the data
- A sink processor is processor that does not have children, it sends the stream data directly to a Kafka topic.
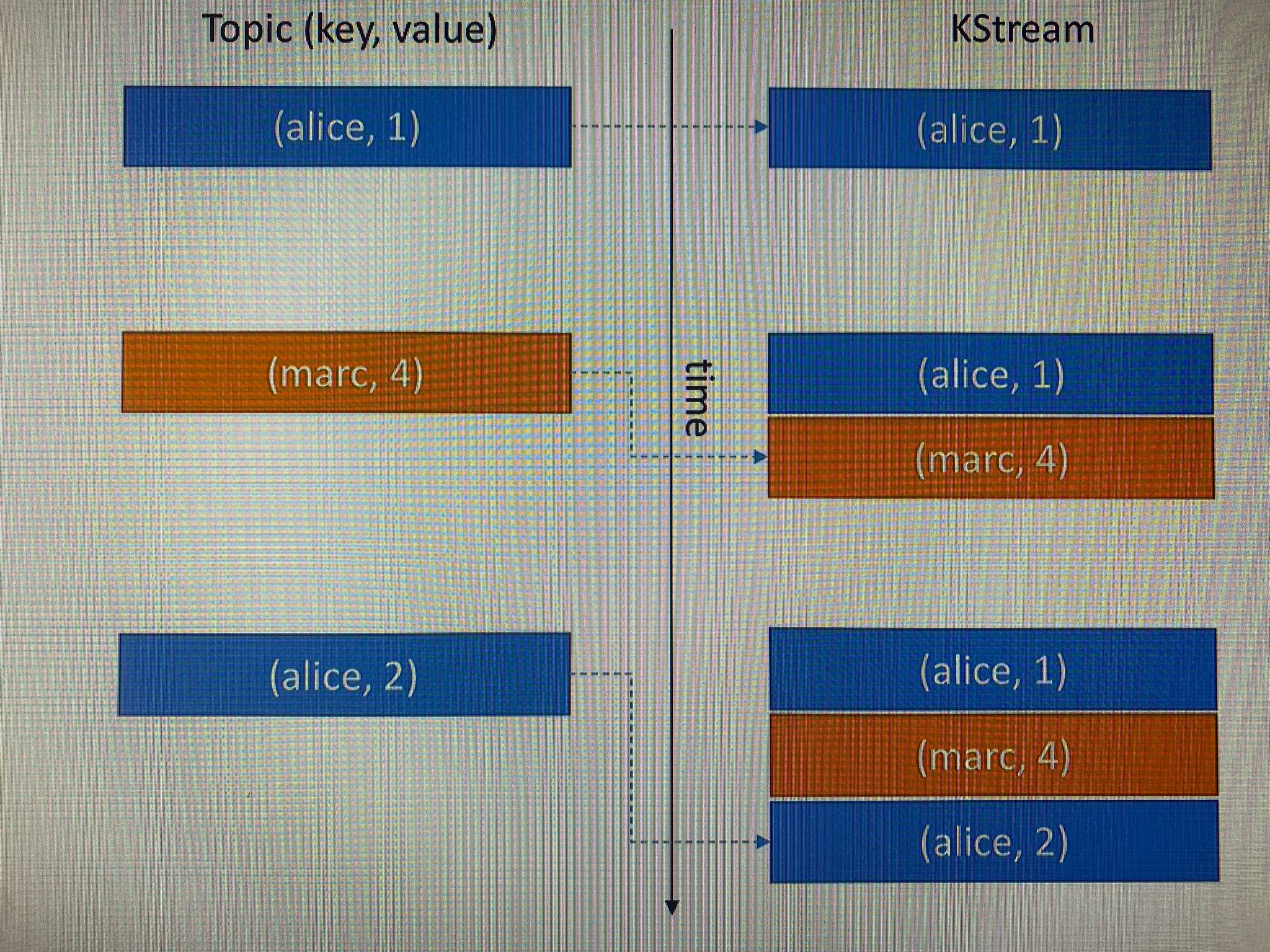
KStream
- All insterts
- Similar to log
- Infinite
- Unbounded data streams
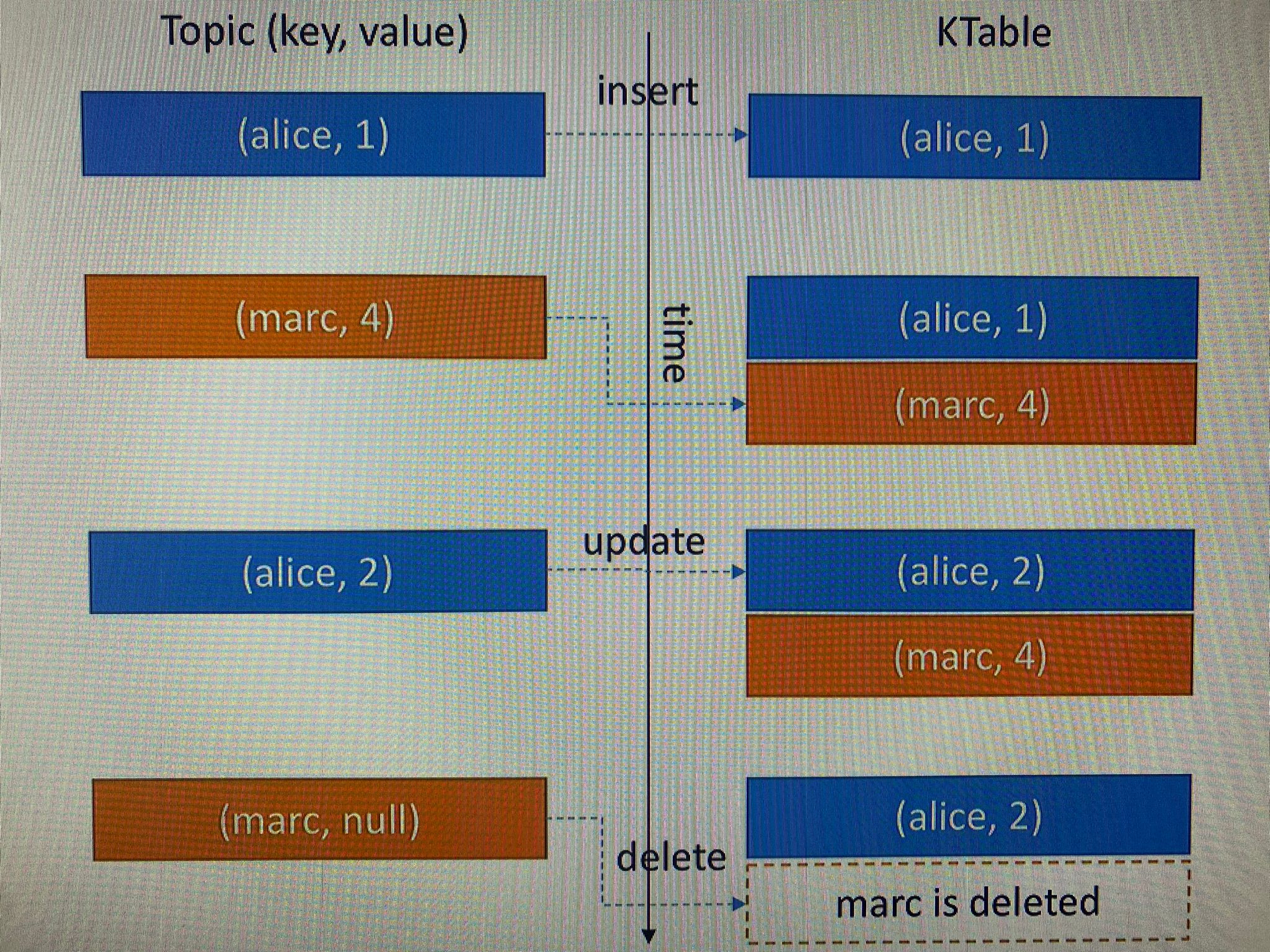
KTable
- All upserts on non null values
- Deletes on null values
- Similar to table
- Parallel with log compacted topics
When to use KStream or KTable?
| KStream | KTable |
|---|---|
| Reading from a topic that’s not compacted | Reading from a topic that’s log-compacted(aggreagations) |
| If new data is partial information/transactional | More if you need a structure that’s like a “database table”, where every update is self sufficient (like total bank balance) |
GlobalKTable
The whole data set will live on every Kafka streams application, and with global tables you can run any stream to your table.
Log Compaction
- Log compaction ensures that your log contains at least the last known value for a specific key within a partition
- Very useful if we just require a SNAPSHOT instead of full history (such as for a data table in database)
- The idea is that we only keep the latest update for a key in out log
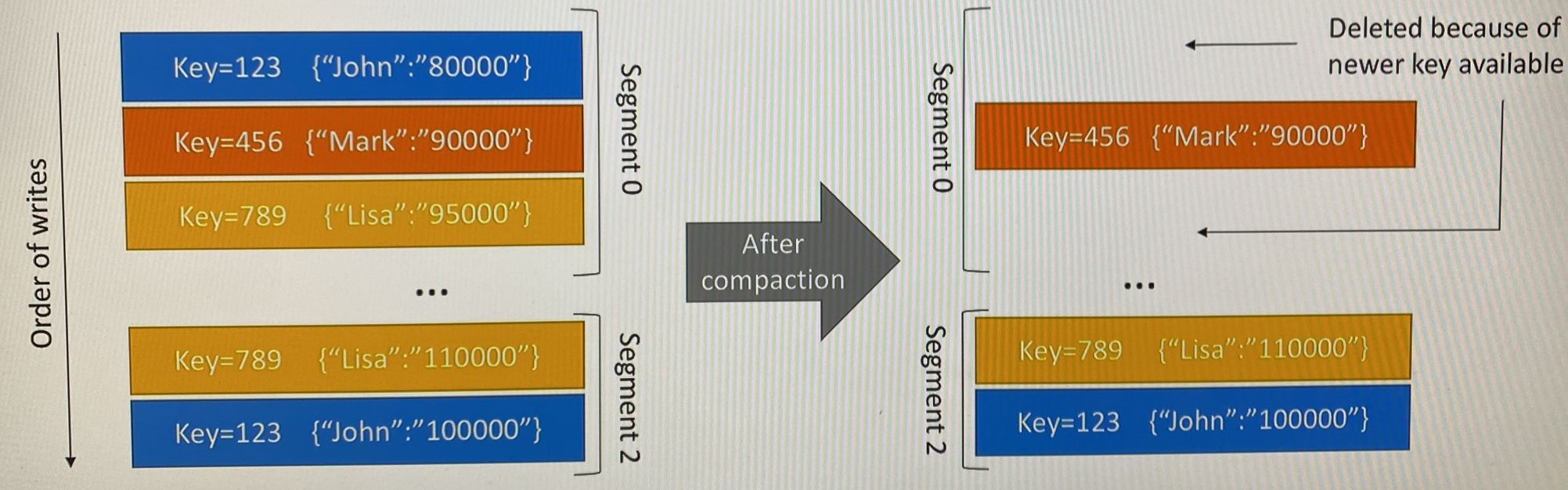
Log Compaction Guarantees
- Any consumer that is reading from the head of a log will still see all the messages sent to the topic
- Ordering of messages it kept, log compaction only removes some messages, but does not re-order them
- The offset of a message is immutable(it never changes). Offsets are just skiipped if a message is missing
- Deleted records can still be seen by consumers for a periof of delete.retention.ms confguration(default is 24 hours).
What doesn’t log compaction do?
- It doesn’t prevent you from pushing duplicate data to Kafka
- De-duplication is done after a segment is committed
- Your consumer will still read from head as soon as the data arrives
- It doesn’t prevent you from reading duplicate data from Kafka
- Same points above
- Log compaction can fail from time to time
- It is an optimization and it the compaction thread might crash
- Make sure you assign enough memory to it and that it gets triggered. But defaults is fine.
KStream & KTable Duality
- Stream as Table : A stream can be considered a changelog of a table, where each data record in the stream captures a state change of the table
- Table as Stream : A table can considered a snapshot, at a point in time, of the latest value for each key in a stream (a stream’s data records are key-value pairs)
Internal Topics
Running a Kafka Streams may eventually create internal intermediary topics.
- Two types:
- Repartitioning topics : in case you start transforming the key of your stream, a repartitioning will happen at some processor.
- Changelog topics : in case you perform aggregations, Kafka Streams will save compacted data in these topics.
Internal topics:
- Are managed by Kafka Streams
- Are used by Kafka Streams to save/restore state and re-partition data
- Are prefixed by application.id parameter
- Should never be deleted, altered or published to. They are internal.
Exactly One Semantics
Exactly once is the ability to guarantee that data processing on each message will happen only once, and that pushing the message back to Kafka will also happen effectively only once ( Kafka will de-dup)
Stateless vs Statefull Operations
- Stateless means that the result of a transformation only depends on the data-point you access
- Example: a “multiply value by 2” operation is stateless because it doesn’t need memory of the past to be achieved
- 1 ⇒ 2
- 300 ⇒ 600
- Stateful means that the result of a transformation also depends on an external information - the state
- Example: a count operation is stateful because your app needs to know what happened since it started running in order to know the computation result
- hello ⇒ 1
- hello �⇒ 2
MapValues/Map
| MapValues | Map |
|---|---|
| Is only affecting values | Affect both key and values |
| == does not change keys | Triggers a re-partition |
| == does not trigger a repartition | For KStream only |
| For KStream and KTable |
Filter/FilterNot
| Filter | FilterNot |
|---|---|
| does not change keys/values | Inverse of Filters |
| == does not trigger a repartition | |
| For KStream and KTable |
FlatMapValues/FlatMap
Takes one record and produces zero, one or more record
| MapValues | Map |
|---|---|
| does not change keys | Change keys |
| == does not trigger a repartition | == triggers a re-partition |
| For KStream only | For KStream only |
Branch
- Branch(split) a KStream based on one or more predicates
- Predicates are evalueated in order, if no matches, records are dropped
- You get multiple KStreams as a result
SelectKey
- Assigns a new Key to the record (from old key and value)
- == marks the data for re-partitioning
- Best practice to isolate that transformation to know exactly where the partitioning happens
To and Through
- To : Terminal operation - write records to a topic
- Through : write to a topic and get a stream/table from the topic ( use case: write data to kafka and continue transformation and write again )
GroupBy
- GroupBy allows you to perform more aggregations within a KTable
- It triggers a repartition because the key chages
Count
- Counts the number of record by grouped key
- If used on KGroupedStream:
- Null keys or values are ignored
- If used on KGroupedTable:
- Null keys are ignored
- Null values are treated as “delete”
Aggregate
- KGroupedStream
- You need an initializer(of any type), an adder, a Serdes and State Store Name(name of your aggregation)
- Example: increase by 2 when add
- KGroupedTable
- You need an initializer(of any type), an adder, a substractor, a Serdes and a State Store Name (name of your aggregation)
- Example : increase by 2 when add and decrease by 2 when delete
Reduce
Similar to Aggregate but the result type has to be the same as an input
Example : (Int,Int) ⇒ Int( example : a * b )
- KGroupedStream
- You need an adder and State Store Name(name of your aggregation)
- KGroupedTable
- You need an adder, a substractor and a State Store Name (name of your aggregation)
Peek
Peek allows you to apply a side-effect operation to a KStream and get the same KStream as a result.
A side effect could be:
- Printing the stream to the console
- Statistics collection
Warning : It coult be executed multiple times as it is side effect (in case of failures)
Join
Joining means taking a KStream and/or KTable and creating a new KStream or KTable from it.
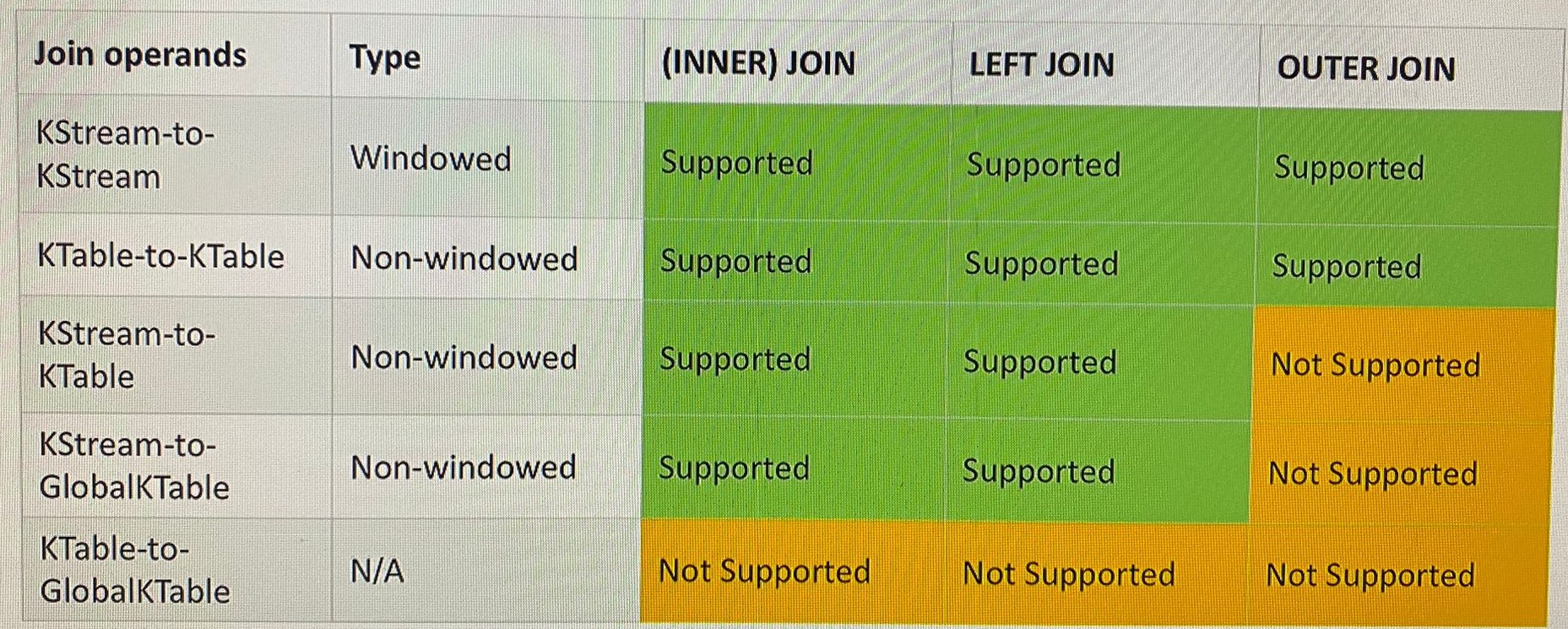
More info : https://www.confluent.io/blog/crossing-streams-joins-apache-kafka/
Streams marked for re-partition
- As soon as an operation can possibly change the key, the stream will be marked for repartition:
- Map
- FlatMap
- SelectKey
- So only use these APIs if you need to change the key, otherwise use their counterparts:
- MapValues
- FlatMapValues
Any anytime you change the key, the data has to be shuffled around. And this shuffling step is what is called spark streaming. It's called shuffling and incurs a network cost. In Kafka, it's called Repartition, where data is written back to Kafka and every other stream application reads it. But now they get data grouped by this new key. So the whole idea behind it is that when you repartition a stream with a key change, the data is redistributed amongst all your streams application. And that's very, very important to know this because basically you want to limit the number of times you change your key and you only do it when you have to because it will incur a cost. It's a small cost, but it's still a cost.
Testing
Provides testing without kafka.